Your text stored perfectly,
retrieved as flawless memory.
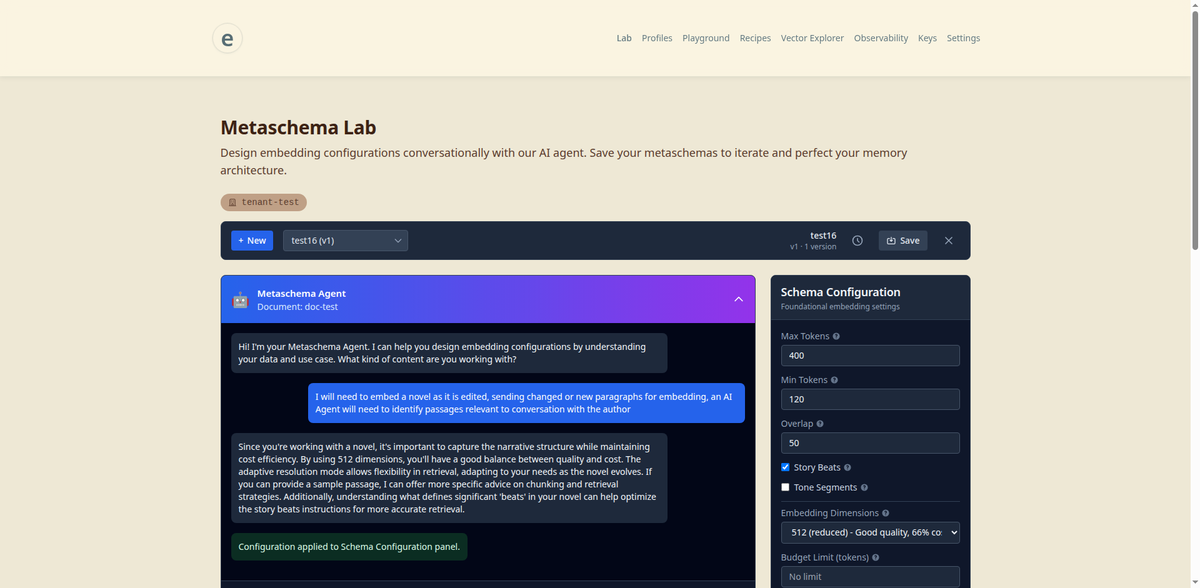
Preserve human meaning with embeddings, evolve memory with instruction and reasoning.
Bidirectional semantic coherence through a unified Metaschema Agent. Deterministic embeddings meet retrieval with zero drift—what you store is exactly what you find.
Developer Portal — Coming Soon
94%
Retrieval Quality
Precision@10 on test corpus
<200ms
Search Speed
P95 latency, multi-layer
Zero
Semantic Drift
EMBED ↔ RETRIEVE coherence
100%
Provenance
Full citation & metadata